By Jas Mehta
In the ever-evolving landscape of science and technology, few stories are as compelling as that of Darnell Granberry, a machine-learning (ML) engineer at the New York Structural Biology Center. His journey from a passionate high school student to a pioneering figure at the intersection of chemistry and artificial intelligence (AI) exemplifies the transformative power of education, mentorship, and relentless curiosity.
Darnell’s fascination with chemistry began in middle school and blossomed during his high school years. His enthusiasm for the subject was evident when he excelled in Advanced Placement (AP) Chemistry as a sophomore. Reflecting on this period, he shared, “I wanted to take AP Chemistry my sophomore year instead of my junior year and was able to do that. I excelled in the class and loved it.” This early exposure to the intricacies of chemical reactions and molecular structures ignited a passion that would shape his future career.
Upon entering college, Darnell initially considered material science but soon found his true calling in chemistry. His interest deepened after taking organic chemistry, a subject that captivated him with its exploration of reaction mechanisms and the fundamental beauty of chemical interactions. This pivotal experience led him to switch his major to chemistry, setting the stage for his future endeavors.
While pursuing his undergraduate degree, Darnell was introduced to the power of computer science through a course on computational structures. This course, which involved building a microprocessor from the ground up, opened his eyes to the immense potential of computational tools in solving complex problems. He was particularly struck by the efficiency and precision of computers in handling intricate calculations, a realization that would influence his future research.
Darnell’s academic journey at the Massachusetts Institute of Technology (MIT) provided a unique opportunity to merge his interests in chemistry and computer science. He took various computational science courses, including computational neuroscience and computational physics, which broadened his understanding of how computational techniques could be applied across different scientific disciplines.
One of the most significant milestones in Darnell’s career was his involvement in AI-driven research. He participated in an internship at the Memorial Sloan Kettering Cancer Center, where he worked on active learning and neural networks to mimic the decision-making processes of a team of scientists in drug discovery. This experience highlighted the potential of AI to revolutionize the field by improving decision-making and efficiency.
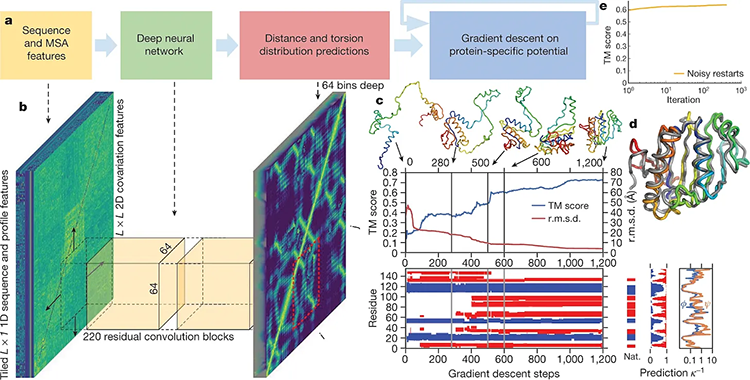
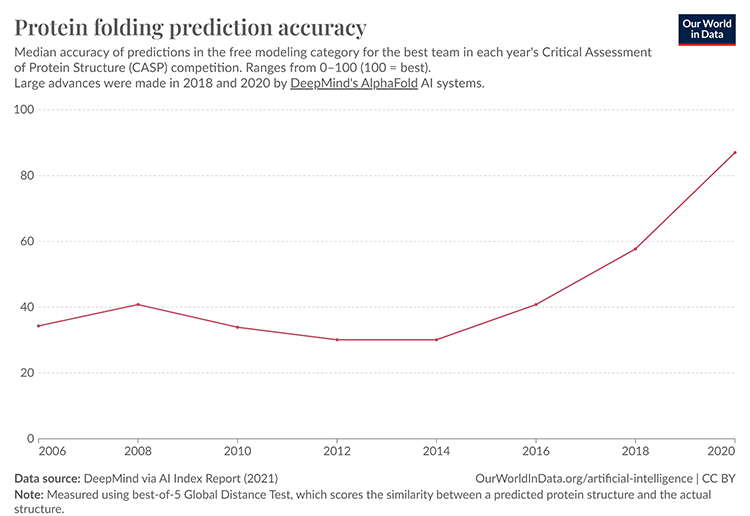
Darnell’s work in this area involved using machine learning to predict the properties of molecules and proteins. (He was featured in a previous story on the roles of deep learning in accelerating protein-folding prediction.) Despite the challenges, his efforts underscored the transformative potential of AI in accelerating drug discovery and developing new therapeutics. The integration of AI in chemistry, particularly through generative modeling and active learning, demonstrated how these technologies could address some of the most pressing challenges in medicine.
In discussing the advancements in his field, Darnell emphasized the exponential growth of computational power, particularly in the development of graphics processing units (GPUs) and supercomputers. He mentioned, “I think the increase in computing power has been the most important advancement. The development of GPUs and supercomputers has made the research move a lot faster.” This increased computational capacity has been instrumental in advancing AI research, making it possible to tackle more complex problems and achieve breakthroughs at an unprecedented pace.
Darnell’s story is a testament to the power of passion, mentorship, and the relentless pursuit of knowledge. His journey from a curious student to a leading figure at the intersection of chemistry and AI serves as an inspiration to future generations of scientists, demonstrating that with the right support and determination, the possibilities are limitless.
Get Involved
Contact the Midwest Big Data Innovation Hub if you’re aware of other people or projects we should profile here, or to participate in any of our community-led Priority Areas. The MBDH has a variety of ways to get involved with our community and activities. The Midwest Big Data Innovation Hub is an NSF-funded partnership of the University of Illinois at Urbana-Champaign, Indiana University, Iowa State University, the University of Michigan, the University of Minnesota, and the University of North Dakota, and is focused on developing collaborations in the 12-state Midwest region. Learn more about the national NSF Big Data Hubs community.